
Your ML Pipeline Is Broken Because You're Not Versioning Anything That Matters
Most teams debug by archaeology. Here's how to fix it with version-controlled packaging and instant rollbacks.
We waste weeks debugging models that worked last month. The code is the same, the notebook hasn’t changed, but somehow the predictions are different. This isn’t a technical mystery—it’s what happens when teams treat ML like software engineering but ignore everything that makes ML actually work.
The reproducibility problem kills velocity. Experiments stop being experiments when you can’t recreate them. Production deployments become gambling when you don’t know what changed between versions. Your team ends up digging through Slack messages and Notion docs trying to remember what hyperparameter someone tweaked three weeks ago.
This isn’t about discipline or better documentation. It’s about missing infrastructure. ML systems depend on three volatile components—code, data, and environment—and most teams only version one of them. Git handles code, but what about the dataset that got updated last Tuesday, or the CUDA version that changed when someone’s laptop got reimaged, or the random seed nobody remembered to set?
The Three Failure Points Nobody Tracks
Code changes constantly. Hyperparameters get adjusted, random seeds get forgotten, training loops get refactored. Stochastic gradient descent and Monte Carlo sampling produce different outputs on every run unless you lock down randomness at every layer. Without tracking your code version alongside the experiment config, you have no idea what produced the model currently serving traffic.
Data is worse. Unlike traditional software, ML depends entirely on training data—and that data grows, gets cleaned, gets corrupted, and gets mislabeled. When someone adds new samples or fixes preprocessing logic, previous results become unreproducible. You need to version both the raw data and every transformation applied to it, or you’re guessing about what trained yesterday’s model.
Environment drift is silent but deadly. TensorFlow updates introduce breaking API changes. PyTorch optimizations alter numeric precision. Different GPU architectures produce subtly different results even with identical code and data. Unless you capture package versions, CUDA configs, and hardware specs, you’re introducing variability you can’t trace.
How to Build Reproducible ML Without Bureaucracy
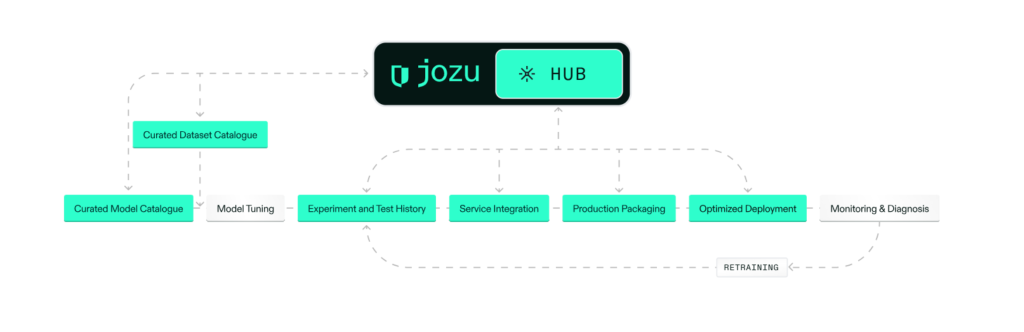
The solution isn’t more process—it’s packaging everything that matters into versioned, immutable bundles. Tools like KitOps let you define your entire project as a YAML manifest (a Kitfile) that captures model weights, training scripts, datasets, and configuration. Package it once, get a ModelKit—a self-contained artifact you can push to a registry, pull into CI/CD, or roll back when production breaks.
This workflow treats ML projects like container images. You define what goes in, package it, tag it with a version, and push it to a registry (like Jozu Hub) where it’s stored immutably. When something fails, you don’t debug—you pull the previous version and redeploy. When an experiment works, you don’t copy-paste commands—you tag the ModelKit and promote it to staging.
The key advantage is traceability without manual logging. Every ModelKit bundles code, data, and metadata, so you can inspect exactly what produced any model version. Comparing iterations becomes a registry operation instead of a forensics exercise. Rolling back becomes a single CLI command instead of rebuilding from scratch.
Production Implementation: Versioning a Recommendation Model
Let’s walk through a real example—building a movie recommendation system, versioning it properly, deploying an update, and rolling back when the update degrades performance. This mirrors what production ML teams deal with constantly: models that need frequent updates, A/B testing, and safe rollback paths.
We’ll build two model versions. Version 1 uses collaborative filtering with cosine similarity between users. Version 2 switches to SVD-based matrix factorization to capture latent features. In production, this kind of algorithm swap happens all the time—teams try new approaches, measure performance, and need the ability to revert quickly if metrics drop.
Building and Packaging Version 1
Start with the MovieLens small dataset (publicly available ratings and movie metadata). Load the ratings, pivot into a user-item matrix, compute cosine similarity between users, and serialize the similarity matrix as a pickle file.
This gives you a trained model saved to ./saved_model/user_similarity_model.pkl.Create a Kitfile that declares everything needed to reproduce this model:
textmanifestVersion: “1.0” package: name: movie-recommend version: 0.0.1 model: name: movie-recommendation-model-v1 path: ./saved_model/user_similarity_model.pkl code: - path: ./movie_recommender.py datasets: - name: ratings-data path: ./datasets/ratings.csv - name: movies-data path: ./datasets/movies.csvPackage it into a ModelKit with kit pack . -t jozu.ml/yourname/movie-recommend:v1.0.0. This bundles the model weights, training script, and datasets into a single OCI-compliant artifact. Push it to the registry with kit push jozu.ml/yourname/movie-recommend:v1.0.0.Deploying Version 2 with Algorithm Changes
Now rewrite the training script to use SVD instead of collaborative filtering. Replace cosine similarity with TruncatedSVD from scikit-learn, fit it on the user-item matrix, and save the fitted SVD model to the same path. This simulates a production scenario where you’re experimenting with a fundamentally different approach to improve recommendation quality.
Update the Kitfile to version 0.0.2, change the model name to movie-recommendation-model-v2, and adjust the description to reflect the SVD approach. Package and push this as v2.0.0. Both versions now exist in the registry, tagged and immutable.
Rolling Back When Version 2 Underperforms
Say version 2 shows worse offline metrics or user engagement drops in A/B testing.
Pull the previous version with kit pull jozu.ml/yourname/movie-recommend:v1.0.0. Unpack it into a local directory with kit unpack jozu.ml/yourname/movie-recommend:v1.0.0 -d ./movie-recommend-v1. This extracts the exact code, data, and model weights from version 1.You’re now back to a known-good state without manually reverting Git commits, hunting for the right dataset snapshot, or remembering which hyperparameters worked. The entire project is self-contained in the ModelKit, so rollback is deterministic.
Why This Matters for Production ML
This workflow solves the core problems that slow down ML teams. Experiments become reproducible because every artifact is versioned together. Deployments become safer because rollbacks are built into the packaging system. Collaboration improves because ModelKits are portable—data scientists can build locally, MLOps can deploy to staging, and DevOps can manage models like any other OCI artifact.
The architectural insight is treating ML projects as immutable packages instead of collections of loosely coupled files. Git is great for code, but ML needs more. By packaging code, data, and environment together, you get atomic versioning across all three components. This eliminates the “works on my machine” problem and the “what changed between last week and today” debugging spiral.
Implementation Considerations
Start by identifying what actually needs to be versioned in your pipeline. Not every dataset needs to be bundled—large training corpora can live in object storage with version hashes in the Kitfile. Focus on capturing the preprocessing steps, the final training data snapshot, and the environment dependencies.
Tag aggressively. Use semantic versioning for models, include Git commit SHAs in Kitfile metadata, and add descriptive tags for experimental branches. This makes comparison easier and rollbacks more intuitive.
Integrate with CI/CD. Automate ModelKit creation on every merge to main, push to a staging registry, run validation tests, and promote to production only after metrics pass thresholds. This turns model deployment into a pipeline operation instead of a manual handoff.
Monitor for environment drift. Even with versioning, production environments change. Use the same container runtime for training and inference, pin dependencies in requirements files, and log hardware specs alongside model metadata. When results differ, you’ll have the data to debug.
What This Enables
Version-controlled ML pipelines unlock rapid iteration. Teams can branch models like code, compare performance across branches, and merge improvements back into production without fear of breaking things. A/B testing becomes safer because rollback is instant.
Regulatory compliance improves. Auditors can trace any production decision back to the exact model version, training data, and code that produced it. Financial services, healthcare, and other regulated industries need this traceability—without it, ML systems are unauditable.
Local-first development works better. Data scientists don’t need cloud credentials to experiment—they can pull ModelKits, unpack them locally, and iterate without touching production infrastructure. DevOps teams don’t need ML expertise—they manage ModelKits like containers and let the registry handle versioning.
Reproducibility stops being a research problem and becomes an engineering primitive. You don’t chase down what changed—you pull the previous version and diff the artifacts. Debugging shifts from forensics to systematic comparison.
Next steps: Install KitOps, define a Kitfile for your current project, and push your first ModelKit to a local registry. Start with a small model, package it, and practice rolling back. Once the workflow feels natural, integrate it into your team’s CI/CD pipeline and make versioned deployments the default.
Amazing augmentation for the good 😊