
The Complete Guide to ML Model Versioning: Why Git Alone Won't Save You
How to stop losing your best models and start shipping ML systems that actually work in production

The Problem Every ML Engineer Has Faced
You train a model. It hits 94% accuracy in your notebook. You’re thrilled. You commit your code to Git, deploy to production, and... it fails spectacularly. Different accuracy. Missing dependencies. Impossible to reproduce. Sound familiar?
This isn’t a bug. It’s a fundamental mismatch between how software engineering works and how machine learning works.
Git was designed to version code. But your model isn’t just code. It’s an emergent property of:
The exact dataset version (including preprocessing, splits, and transformations)
Hyperparameters and training configurations
The stochastic training process itself (random seeds, optimization trajectories)
Environment state (Python version, CUDA version, library dependencies)
The trained weights (often gigabytes in size)
When any of these change, your model changes. And Git can’t track most of them.
This article shows you how to solve this using two complementary tools: Weights & Biases for experiment tracking and KitOps for production packaging. We’ll build a complete MLOps pipeline that gives you end-to-end lineage from experimentation to deployment.
Understanding the MLOps Versioning Problem
Let’s break down why traditional version control fails for ML:
1. The Data Problem
Your model depends on specific data. But data changes:
New samples arrive continuously
Labels get corrected
Preprocessing pipelines evolve
Train/test splits need to be frozen
Git LFS can store large files, but it doesn’t capture the semantic versioning you need: “Which exact rows from which exact table at which exact timestamp trained this model?”
2. The Reproducibility Problem
Two weeks later, your teammate asks: “Can you reproduce that model from Sprint 3?”
Can you remember:
The exact hyperparameters?
Which preprocessing do you use?
What
sklearnversion was installed?The random seed for the train/test split?
Probably not. And even if you documented it manually, can you be certain nothing else changed?
3. The Deployment Problem
You want to deploy a model. Security asks: “What dependencies does this model have? Are there known vulnerabilities?”
You don’t know. The model is a pickle file. It’s opaque. There’s no manifest, no audit trail, no way to verify integrity.
This is where software engineering had Docker. ML needs something similar.
The Solution: Experiment Tracking + Production Packaging
The key insight is that ML has two distinct phases with different requirements:
Experimentation Phase: You’re running dozens or hundreds of training runs, comparing architectures, tuning hyperparameters, trying different data augmentations. You need to track everything automatically so you can compare runs and find what works.
Production Phase: You’ve found a good model. Now you need to package it with everything required to reproduce or deploy it: model weights, dataset metadata, code, dependencies, and documentation. You need guarantees about security, reproducibility, and auditability.
Weights & Biases handles the first phase. KitOps handles the second. Together, they give you a complete lineage.
How Weights & Biases Works
W&B automatically logs everything about your training runs:
python
import wandb
wandb.init(
project=”my-project”,
config={
“learning_rate”: 0.001,
“batch_size”: 32,
“architecture”: “resnet50”
}
)
# Train your model...
for epoch in range(epochs):
loss = train_epoch()
wandb.log({”loss”: loss, “epoch”: epoch})What gets logged automatically:
Hyperparameters: Everything in your config
Metrics: Accuracy, loss, custom metrics over time
System info: GPU utilization, memory, training duration
Code version: Git commit hash if using version control
Environment: Library versions, Python version
This creates a permanent, searchable record. You can compare runs side-by-side, see which hyperparameters improved performance, and reproduce any experiment exactly.
W&B Artifacts: Versioning Beyond Metrics
W&B Artifacts let you version the actual model files and datasets:
python
# Create a versioned artifact
artifact = wandb.Artifact(
name=’my-model’,
type=’model’,
metadata={
‘accuracy’: 0.94,
‘architecture’: ‘resnet50’
}
)
# Add model file
artifact.add_file(’model.pth’)
# Log it (automatically gets version number: v0, v1, v2...)
run.log_artifact(artifact)Now your model files are versioned and tied to the training run that produced them. This is crucial for the next step.
How KitOps Works
KitOps packages your model into a ModelKit: a self-contained, OCI-compliant artifact that includes everything needed to reproduce or deploy your model.
Think of it like Docker for ML models. Just as Docker containers bundle an application with all its dependencies, ModelKits bundle models with all their dependencies.
The Kitfile: A Manifest for ML Models
The Kitfile is the manifest that describes your ModelKit:
yaml
manifestVersion: 1.0
package:
name: sentiment-analysis
version: 1.0.0
description: Sentiment analysis model for customer reviews
authors: [”Your Team”]
license: MIT
model:
name: sentiment-classifier
path: models/model.pkl
framework: scikit-learn
version: 1.0.0
metadata:
accuracy: 0.94
training_date: “2025-01-15”
wandb_run_id: “abc123”
code:
- path: train.py
description: Training script
- path: preprocess.py
description: Data preprocessing
datasets:
- name: training-data
path: data/train.csv
description: Training dataset snapshot
dependencies:
- scikit-learn==1.2.0
- numpy==1.24.0
- pandas==2.0.0This manifest is human-readable and contains everything someone needs to understand what’s in your model artifact.
What Makes ModelKits Powerful
OCI Compliance: ModelKits use the same standard as Docker images. They can be stored in any OCI-compliant registry, pushed/pulled like containers, and benefit from existing container infrastructure.
Automatic SBOM Generation: When you package a ModelKit, KitOps automatically generates a Software Bill of Materials (SBOM). This is a complete inventory of every component in your ML system: model weights, datasets, libraries, and versions. Critical for security audits and compliance.
Immutability: Once created, ModelKits are immutable. Content-addressable storage means any tampering is immediately detectable.
Portability: Because everything is bundled together, ModelKits run the same way everywhere: cloud, edge devices, and on-premises servers.
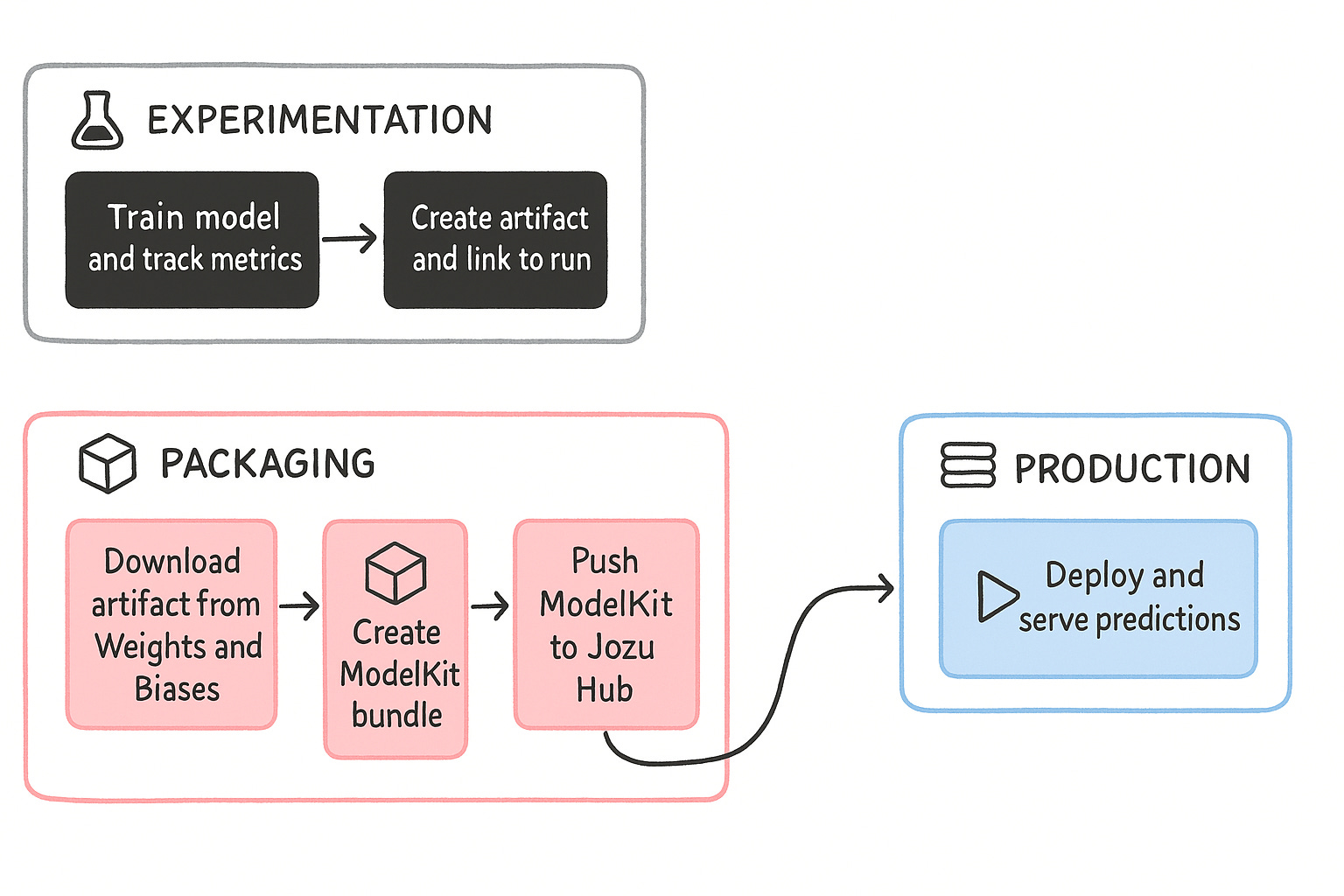
Building a Complete MLOps Pipeline: A Technical Walkthrough
Let’s build a complete pipeline that demonstrates these principles. We’ll train a sentiment analysis model, track it with W&B, and package it with KitOps.
Prerequisites
You’ll need accounts for:
Weights & Biases - Get your API key after signup
Jozu Hub - For storing ModelKits
Install dependencies:
bash
pip install wandb scikit-learn joblib matplotlib python-dotenv kitopsStep 1: Training with W&B Tracking
Here’s the complete training script with W&B integration:
python
import wandb
import numpy as np
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from sklearn.model_selection import train_test_split
import joblib
import os
# Initialize W&B - this starts tracking
wandb.login()
run = wandb.init(
project=”sentiment-analysis-production”,
name=”logistic-regression-baseline”,
config={
“model”: “LogisticRegression”,
“max_features”: 5000,
“C”: 1.0,
“solver”: “lbfgs”,
“max_iter”: 1000,
“test_size”: 0.2,
“random_state”: 42
}
)
config = wandb.config
# Load dataset - binary text classification
categories = [’alt.atheism’, ‘soc.religion.christian’]
train_data = fetch_20newsgroups(
subset=’train’,
categories=categories,
shuffle=True,
random_state=42
)
test_data = fetch_20newsgroups(
subset=’test’,
categories=categories,
shuffle=True,
random_state=42
)
X_train, y_train = train_data.data, train_data.target
X_test, y_test = test_data.data, test_data.target
# Create validation split
X_train, X_val, y_train, y_val = train_test_split(
X_train, y_train,
test_size=0.2,
random_state=config.random_state
)
# Feature extraction
vectorizer = TfidfVectorizer(
max_features=config.max_features,
stop_words=’english’
)
X_train_tfidf = vectorizer.fit_transform(X_train)
X_val_tfidf = vectorizer.transform(X_val)
X_test_tfidf = vectorizer.transform(X_test)
# Train model
model = LogisticRegression(
C=config.C,
solver=config.solver,
max_iter=config.max_iter,
random_state=config.random_state
)
model.fit(X_train_tfidf, y_train)
# Evaluate
y_val_pred = model.predict(X_val_tfidf)
y_test_pred = model.predict(X_test_tfidf)
# Calculate metrics
metrics = {
“val_accuracy”: accuracy_score(y_val, y_val_pred),
“test_accuracy”: accuracy_score(y_test, y_test_pred),
“test_precision”: precision_score(y_test, y_test_pred),
“test_recall”: recall_score(y_test, y_test_pred),
“test_f1”: f1_score(y_test, y_test_pred)
}
# Log to W&B
wandb.log(metrics)
# Log confusion matrix
wandb.log({
“confusion_matrix”: wandb.plot.confusion_matrix(
probs=None,
y_true=y_test,
preds=y_test_pred,
class_names=categories
)
})
# Save model files
os.makedirs(’models’, exist_ok=True)
joblib.dump(model, ‘models/sentiment_model.pkl’)
joblib.dump(vectorizer, ‘models/vectorizer.pkl’)
print(f”Test Accuracy: {metrics[’test_accuracy’]:.2%}”)
print(f”W&B Run: {run.url}”)What’s happening here:
wandb.init()creates a new run and logs your config automaticallyAll metrics logged with
wandb.log()become searchable and comparableThe confusion matrix becomes an interactive visualization in W&B
Model files are saved locally for the next step
Step 2: Version as a W&B Artifact
Now we create a versioned artifact in W&B:
python
# Create artifact with rich metadata
artifact = wandb.Artifact(
name=’sentiment-analysis-model’,
type=’model’,
description=’Logistic Regression sentiment classifier with TF-IDF features’,
metadata={
‘model_type’: ‘LogisticRegression’,
‘framework’: ‘scikit-learn’,
‘task’: ‘binary_text_classification’,
‘categories’: categories,
**metrics # Include all test metrics
}
)
# Add model files
artifact.add_file(’models/sentiment_model.pkl’)
artifact.add_file(’models/vectorizer.pkl’)
# Log artifact - W&B automatically versions this (v0, v1, v2...)
run.log_artifact(artifact)
wandb.finish()
print(f”Artifact logged: sentiment-analysis-model:v0”)Critical insight: The artifact is now permanently linked to the training run. Six months from now, you can look at this model in production, trace it back to the W&B artifact, and see:
The exact hyperparameters used
The training metrics and curves
The code version (Git commit)
The environment (library versions)
The training duration and resource usage
Step 3: Package as a ModelKit
Now we download the W&B artifact and package it with KitOps:
python
import wandb
import os
from dotenv import load_dotenv
# Download the W&B artifact
wandb.login()
api = wandb.Api()
artifact = api.artifact(
‘your-entity/sentiment-analysis-production/sentiment-analysis-model:latest’
)
artifact_dir = artifact.download()
# Paths to downloaded files
model_path = os.path.join(artifact_dir, ‘sentiment_model.pkl’)
vectorizer_path = os.path.join(artifact_dir, ‘vectorizer.pkl’)
# Get metadata from W&B
metadata = artifact.metadataCreate the Kitfile:
python
from kitops.modelkit.kitfile import Kitfile
from kitops.modelkit.manager import ModelKitManager
# Create Kitfile manifest
kitfile = Kitfile()
kitfile.manifestVersion = “1.0”
kitfile.package = {
“name”: “sentiment-analysis-sklearn”,
“version”: “1.0.0”,
“description”: “Production-ready sentiment analysis model”,
“authors”: [”ML Team”],
“license”: “MIT”
}
kitfile.model = {
“name”: “sentiment-classifier”,
“path”: model_path,
“framework”: “scikit-learn”,
“version”: “1.0.0”,
“description”: “Logistic Regression with TF-IDF features”,
“license”: “MIT”,
“metadata”: metadata # W&B metadata preserved in ModelKit
}
kitfile.code = [
{
“path”: “train.py”,
“description”: “Training script”,
“license”: “MIT”
},
{
“path”: vectorizer_path,
“description”: “TF-IDF vectorizer (required for inference)”,
“license”: “MIT”
}
]
# Save Kitfile
kitfile.save(”Kitfile”)Step 4: Push to Jozu Hub
Configure credentials in a .env file:
JOZU_USERNAME=your_email@example.com
JOZU_PASSWORD=your_password
JOZU_NAMESPACE=your_usernamePush the ModelKit:
python
load_dotenv()
namespace = os.getenv(”JOZU_NAMESPACE”)
modelkit_tag = f”jozu.ml/{namespace}/sentiment-analysis-sklearn:v1.0.0”
# Pack and push
manager = ModelKitManager(
working_directory=”.”,
modelkit_tag=modelkit_tag
)
manager.kitfile = kitfile
manager.pack_and_push_modelkit(save_kitfile=True)
print(f”ModelKit pushed to {modelkit_tag}”)What just happened:
KitOps bundled your model, vectorizer, code, and metadata into a single artifact
It generated an SBOM listing every dependency
It pushed the artifact to Jozu Hub using OCI standard protocols
The artifact is now immutable and content-addressed (tampering is detectable)
Step 5: Deploy and Use
Anyone can now pull your ModelKit:
bash
kit pull jozu.ml/your-namespace/sentiment-analysis-sklearn:v1.0.0
kit unpack jozu.ml/your-namespace/sentiment-analysis-sklearn:v1.0.0 -d ./modelThis extracts:
sentiment_model.pkl- The trained modelvectorizer.pkl- The TF-IDF vectorizertrain.py- The training scriptKitfile- The complete manifestSBOM.json- Software Bill of Materials
Load and use the model:
python
import joblib
model = joblib.load(’model/sentiment_model.pkl’)
vectorizer = joblib.load(’model/vectorizer.pkl’)
# Inference
text = [”This product is amazing!”, “Worst purchase ever.”]
features = vectorizer.transform(text)
predictions = model.predict(features)The Complete Lineage: From Experiment to Production
Here’s the power of this approach. Suppose your model fails in production six months from now. Here’s how you debug it:
Check Jozu Hub: See the exact ModelKit version deployed
Check the Kitfile: See the W&B run ID in the metadata
Check W&B: See the exact training run with all hyperparameters, metrics, and environment info
Check the SBOM: See all dependencies and versions
Check the dataset artifact: See the exact data used for training
You now know exactly what produced this model. You can reproduce it precisely or identify what changed.
Production Considerations
Security and Compliance
The SBOM generated by KitOps is critical for security:
json
{
“bomFormat”: “CycloneDX”,
“specVersion”: “1.4”,
“components”: [
{
“type”: “library”,
“name”: “scikit-learn”,
“version”: “1.2.0”,
“purl”: “pkg:pypi/scikit-learn@1.2.0”
},
{
“type”: “library”,
“name”: “numpy”,
“version”: “1.24.0”,
“purl”: “pkg:pypi/numpy@1.24.0”
}
]
}You can now:
Scan for known vulnerabilities (CVEs)
Enforce policies (block models with critical vulnerabilities)
Maintain audit trails for compliance
Track supply chain security
Governance and Audit Trails
Jozu Hub provides:
Complete audit logs: Who deployed what, when, and where
Policy enforcement: Block deployments that fail security scans
Immutable history: All changes are tracked and verifiable
This is critical in regulated industries (healthcare, finance) where you need to prove compliance.
Versioning Strategy
Adopt semantic versioning for ModelKits:
Major version (v2.0.0): Architecture changes, breaking API changes
Minor version (v1.1.0): Retrained with new data, improved accuracy
Patch version (v1.0.1): Bug fixes, dependency updates
Tag models with metadata:
bash
kit tag jozu.ml/namespace/model:v1.0.0 production
kit tag jozu.ml/namespace/model:v1.1.0 stagingCommon Pitfalls and Solutions
Pitfall 1: Forgetting to Log Everything
Problem: You log accuracy but forget to log the learning rate schedule, data augmentation parameters, or early stopping criteria.
Solution: Log your entire config object to W&B at the start:
python
config = {
# Model hyperparameters
“learning_rate”: 0.001,
“batch_size”: 32,
# Data parameters
“data_augmentation”: True,
“train_split”: 0.8,
# Training parameters
“early_stopping_patience”: 5,
“max_epochs”: 100
}
wandb.init(project=”my-project”, config=config)Pitfall 2: Not Versioning Datasets
Problem: You version your model but not your training data. Six months later, you can’t reproduce the model because the data has changed.
Solution: Use W&B Artifacts for datasets too:
python
dataset_artifact = wandb.Artifact(
name=’training-data’,
type=’dataset’,
description=’Training data snapshot for Q1 2025’
)
dataset_artifact.add_file(’data/train.csv’)
run.log_artifact(dataset_artifact)Pitfall 3: Incomplete Model Kits
Problem: You package the model weights but forget the preprocessing code or the feature engineering pipeline.
Solution: Include everything needed for inference:
Model weights
Preprocessing scripts
Vectorizers/tokenizers/scalers
Configuration files
Example inputs/outputs
Documentation
Pitfall 4: Not Testing Reproducibility
Problem: You assume your ModelKit is reproducible but never actually test it.
Solution: After pushing a ModelKit, pull it in a clean environment and verify:
bash
# Pull ModelKit
kit pull jozu.ml/namespace/model:v1.0.0
# Unpack it
kit unpack jozu.ml/namespace/model:v1.0.0 -d test-env
# Run inference and compare results
python test-env/inference.pyCompare outputs with your original validation results. They should match exactly.
Advanced Patterns
Pattern 1: Multi-Stage Model Kits
For complex pipelines (e.g., ensemble models), create ModelKits that reference other ModelKits:
yaml
models:
- name: feature-extractor
path: models/resnet50.pth
- name: classifier-head
path: models/classifier.pth
dependencies:
- modelkit: jozu.ml/namespace/resnet50-pretrained:v2.1.0Pattern 2: Dataset Lineage
Track which ModelKits were trained on which datasets:
yaml
model:
metadata:
dataset_artifact: “customer-reviews:v3”
dataset_hash: “sha256:abc123...”
training_samples: 50000
validation_samples: 10000Pattern 3: A/B Testing Metadata
Tag models with experiment variants:
yaml
model:
metadata:
experiment: “reduced-latency-v2”
variant: “B”
target_metric: “inference_latency_ms”
target_value: 45Troubleshooting Guide
W&B Authentication Issues
bash
# Re-authenticate
wandb login --relogin
# Set API key via environment variable
export WANDB_API_KEY=your_key_hereKitOps Push Failures
bash
# Check authentication
kit login jozu.ml
# Verify namespace
kit config show
# Test with dry-run
kit pack --dry-runReproducibility Mismatches
If you can’t reproduce results:
Check library versions in SBOM vs your environment
Verify random seeds match
Confirm dataset version is identical (check hashes)
Compare W&B runs for environmental differences
Check for non-deterministic operations (GPU ops, dropout without seeding)
ModelKit Size Issues
If ModelKits are too large:
Use model compression (quantization, pruning)
Reference external datasets rather than embedding them
Use model registries for base models (don’t duplicate pre-trained weights)
Layer your ModelKits (separate large static components from frequently updated ones)
Conclusion: The Path to Production ML
The combination of W&B and KitOps solves the fundamental versioning problem in machine learning:
W&B gives you complete experiment tracking: every run, every metric, every hyperparameter is logged automatically
KitOps gives you production packaging: reproducible, secure, portable artifacts with complete dependency manifests
Together, they create end-to-end lineage from experimentation to deployment. No more “works on my machine” problems. No more mysterious production failures. No more inability to reproduce past results.
This is what production ML looks like in 2025. The tools have caught up to the complexity of the problem.
The next time you train a model, you’ll know exactly:
What data trained it
What hyperparameters produced it
What dependencies it need
Whether it has security vulnerabilities
How to reproduce it exactly
Who deployed it and when
That’s not just version control. That’s production-grade ML engineering.
Further Reading
This post walks through building a complete MLOps pipeline with practical code examples. For questions or feedback, feel free to reach out.
Brilliant. This is so spot on, I totally get it. What if someone on your team makes a tiny, accidental tweak to a preprocessing step or updates a library? Without proper data and environment versioning, debugging a performance drop later is practically imposibile. Oof, the headaches.
Thanks for the ModelOps guide to the same for the good 😊