
How to Deploy ML Models Like Code: A Practical Guide to KitOps and Flux CD
Or: The day I stopped manually deploying models and started actually sleeping at night

Here’s a truth bomb that’ll resonate with every ML engineer who’s ever pushed to production: getting a model to work in a Jupyter notebook is the easy part. The hard part? Making sure it doesn’t explode when someone else tries to run it three months later.
You know the drill. Your data scientist sends you a Slack message: “Hey, the model’s ready!” You get a zip file. Maybe a Google Drive link if you’re lucky. Inside? A tangled mess of:
A model file (which version, though?)
Some Python scripts (do they even run?)
A requirements.txt that’s definitely lying about its dependencies
A dataset that may or may not be the one used for training
Zero documentation because “the code is self-documenting”
And now you’re supposed to deploy this to production. With confidence. While maintaining your sanity.
The Three Horsemen of ML Deployment Hell
Let me paint you a picture of what typically goes wrong:
Problem 1: Packaging is Broken
Traditional packaging tools were built for web apps, not ML models. They choke on the massive files ML projects produce. Ever tried cramming a 2GB model into a standard package format? It’s like trying to fit an elephant into a Mini Cooper. Technically possible, maybe, but why would you?
Problem 2: The Trust Problem
Here’s a fun game: try proving that the model running in production is exactly the one your data scientist trained last Tuesday. Can’t do it? Welcome to the club. Without tamper-proof guarantees, you’re basically crossing your fingers and hoping nobody accidentally (or maliciously) swapped out your sentiment analysis model for one trained on Reddit comments from 2016.
Problem 3: Deployment Pipelines That Weren’t Built for This
Your deployment pipeline was designed for stateless microservices that restart in milliseconds. ML models? They’re the opposite. They’re stateful, heavy, and take their sweet time to load. Traditional CI/CD tools treat them like any other app, which is like using a regular oven to bake a soufflé—technically it’s an oven, but you’re gonna have a bad time.
Enter: The Dream Team
What if I told you there’s a better way? Not a “revolutionary new framework that’ll be deprecated next quarter” better way, but a “let’s use purpose-built tools that actually understand our problems” better way.
Meet your new best friends:
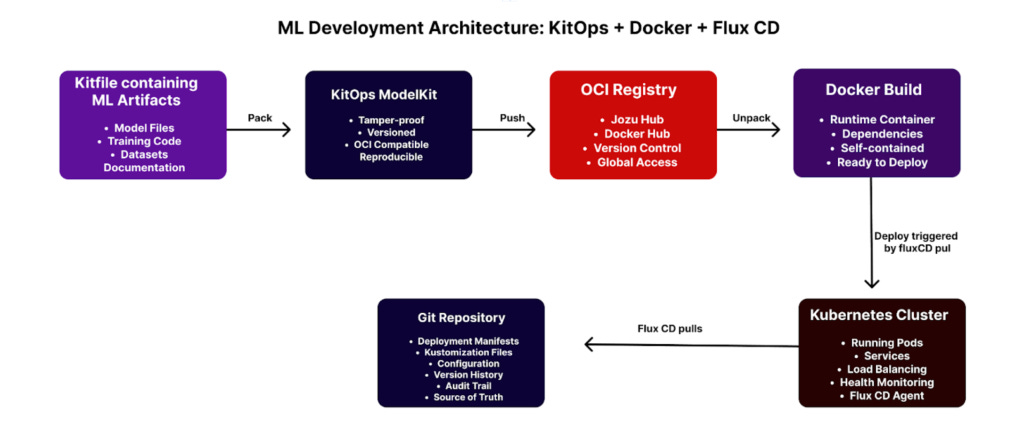
KitOps: The Packaging Savant
Think of KitOps as a specialized moving company for ML projects. It doesn’t just throw everything in a box—it creates a ModelKit, which is basically a tamper-proof, versioned container that holds:
Your trained model
The exact code used
Datasets (or references to them)
Documentation (yes, actual docs!)
All dependencies, frozen in time
The magic? It’s built on OCI (Open Container Initiative) standards, which means it plays nice with every container registry you already use. No new infrastructure. No vendor lock-in. Just a better way to package ML artifacts.
Flux CD: The Deployment Zen Master
Flux CD brings GitOps to ML deployments, and it’s about time. Instead of you pushing changes to production (and holding your breath), Flux lives inside your Kubernetes cluster and pulls from Git as its source of truth.
This flip in perspective is huge:
Security: No cluster credentials floating around in CI/CD pipelines
Drift detection: If someone manually changes something in production (we all know it happens), Flux automatically fixes it
Declarative everything: Your Git repo describes what should be running. Flux makes it happen.
How They Work Together (The Good Stuff)
Here’s the workflow that’ll make your life better:
1. Package Your Model
bash
kit pack . -t jozu.ml/yourname/sentiment-model:1.0.0
kit push jozu.ml/yourname/sentiment-model:1.0.0Boom. Your model, code, and everything else is now a versioned artifact in a registry. Tamper-proof. Shareable. Actually reproducible.
2. Build a Runtime Container
Create a Dockerfile that knows how to serve your model:
dockerfile
FROM python:3.10-slim
# Install KitOps
RUN curl -sSL https://github.com/kitops-ml/kitops/releases/latest/download/kitops-linux-x86_64.tar.gz | tar -xvz --directory /usr/local/bin
# Unpack the ModelKit
RUN kit unpack jozu.ml/yourname/sentiment-model:1.0.0 -d /app
# Install dependencies and run
RUN pip install -r requirements.txt
EXPOSE 8000
CMD [”python”, “code/inference.py”]Notice what’s happening? The ModelKit is separate from the runtime container. This is huge. Data scientists can update models without touching Docker. DevOps can update infrastructure without touching model code.
3. Let Flux Handle Deployment
Commit your Kubernetes manifests to Git:
yaml
# deployment.yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: sentiment-classifier
spec:
replicas: 3
template:
spec:
containers:
- name: model-runtime
image: yourname/sentiment-runtime:1.0.0
ports:
- containerPort: 8000Push to Git. Walk away. Flux detects the change and deploys it. No kubectl apply. No manual steps. Just pure, declarative bliss.
The Real Win: Updates Without Pain
Here’s where this workflow really shines. Your data scientist retrained the model with fresh data. In the old world? Chaos. Slack messages. Zoom calls. Manual deployments. Prayers.
In the new world:
Data scientist packages the new model:
kit pack→kit pushYou update one line in Git:
image: yourname/sentiment-runtime:1.0.9You push to Git
Flux notices, pulls the new image, and rolls it out
You go get coffee
That’s it. That’s the whole process. No ticket systems. No deployment windows. No holding your breath.
Why This Matters
Look, I get it. Adding new tools to your stack feels like adding more complexity. But here’s the thing: you already have these problems. You’re already dealing with model versioning chaos. You’re already manually deploying to production. You’re already playing “guess which dataset this model was trained on.”
KitOps and Flux don’t add complexity—they replace complexity with structure. They take the ad-hoc, error-prone processes you’re doing manually and make them repeatable, auditable, and actually reliable.
Plus, they’re both open source. No vendor lock-in. No enterprise sales calls. Just tools built by people who’ve felt your pain.
The Bottom Line
Moving ML models to production doesn’t have to feel like defusing a bomb while blindfolded. With the right tools—tools actually designed for ML workflows—it can be almost boring. And boring, in operations, is exactly what you want.
So next time your data scientist Slacks you “the model’s ready,” you can just say: “Cool, pack it with KitOps and push to Git. Flux will handle the rest.” And then you can go back to whatever you were doing, knowing that your deployment pipeline is handling it like a professional instead of like a caffeinated intern.
That’s the dream. And unlike most things in tech, this one’s actually achievable.
Want to try this out? The full tutorial with all the code is available in the documentation. Fair warning: once you experience GitOps for ML, going back to manual deployments feels like writing API responses by hand.
What’s your current ML deployment process? Hit reply and share your horror stories with me. I collect them.
Mission accomplished 👏🏽💃🏽🥰