Context Engineering 2.0: Building Production-Ready RAG Systems
The real game isn't just about what context you provide—it's about building systems that can reliably provide the right context at scale.

If you read my original post on context engineering, you know it’s about crafting the perfect context for LLMs. But here’s what I’ve learned since: the real game isn’t just about what context you provide—it’s about building systems that can reliably provide the right context at scale.
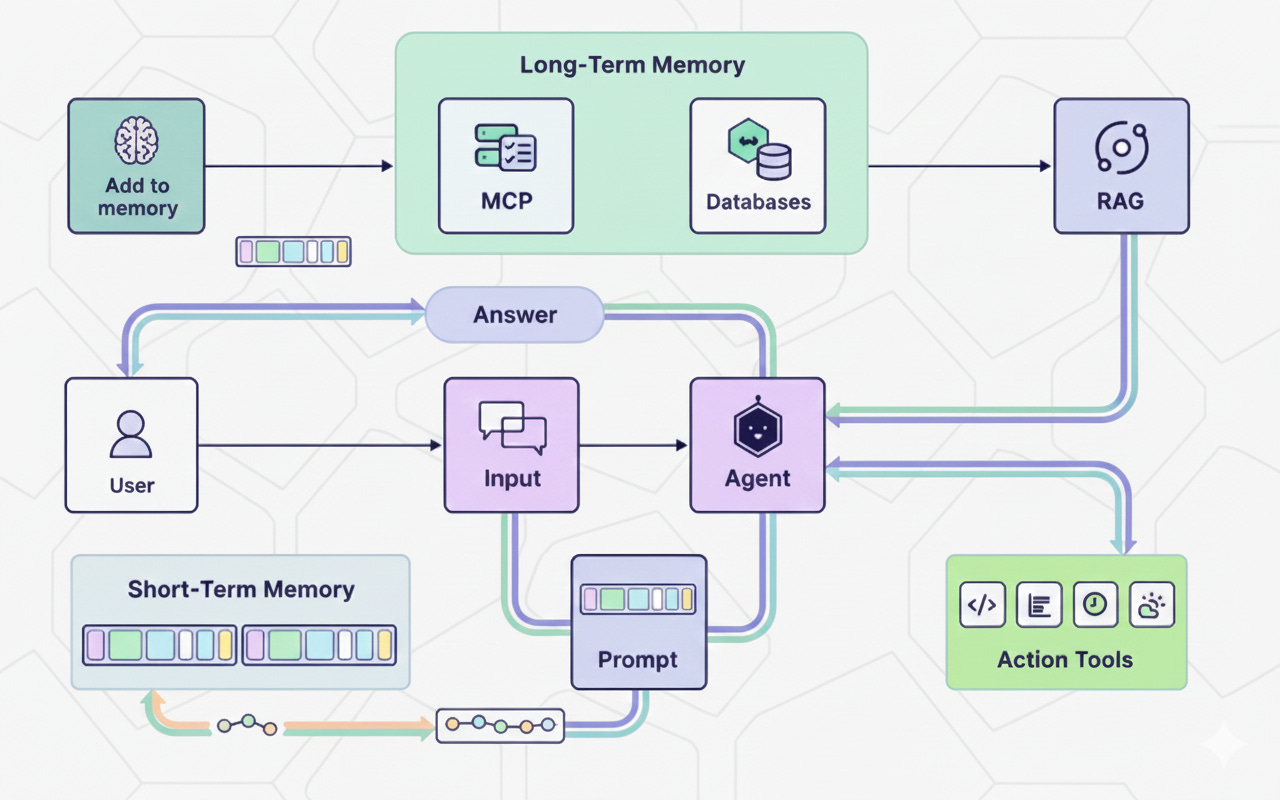
From Theory to Production
The original context engineering focused on the fundamentals: chunking strategies, prompt design, and basic retrieval. That was version 1.0. Now we need to talk about what it takes to build RAG systems that actually work in production.
The gap between a demo and a production RAG system is enormous. Your demo might work beautifully on cherry-picked examples, but production means handling:
Queries you never anticipated
Documents that don’t fit your assumptions
Users who phrase things in unexpected ways
Scale that breaks your naive implementations
The Core Challenge: Retrieval Quality
Here’s the uncomfortable truth: most RAG failures are retrieval failures, not generation failures.
Your LLM is probably fine. Claude, GPT-4, Gemini—they’re all incredibly capable. But if you’re feeding them irrelevant context, even the best model will give you garbage answers.
Think about it this way: if you asked a brilliant researcher to write a report but only gave them the wrong source materials, would you blame them for the bad report?
The Three Pillars of Production RAG
1. Chunking Strategy
Forget fixed 512-token chunks. Production systems need intelligent segmentation:
Semantic chunking: Break documents at natural boundaries (paragraphs, sections, topic shifts)
Context-aware sizing: Keep related information together even if it exceeds your target chunk size
Overlap management: Strategic overlap between chunks so you don’t lose information at boundaries
The goal isn’t uniform chunks—it’s meaningful chunks.
2. Hybrid Search Architecture
Dense vector search alone isn’t enough. You need hybrid retrieval:
Dense retrieval (embeddings): Great for semantic similarity and conceptual matching
Sparse retrieval (BM25/keyword): Crucial for exact matches, proper nouns, technical terms
Weighted fusion: Combine both approaches, adjusting weights based on your use case
Why? Because some queries need semantic understanding (”what causes climate change?”) while others need exact matching (”find the Q3 2023 revenue figure”).
3. Reranking
This is the secret weapon most people skip. After initial retrieval:
Retrieve more candidates than you need (say, 50 chunks)
Use a cross-encoder to rerank based on actual relevance to the query
Select the top K (maybe 5-10) for your final context
Reranking dramatically improves precision because cross-encoders can evaluate query-document pairs directly, not just compare embeddings in vector space.
Advanced Techniques That Actually Matter
Query Transformation
Don’t just use the user’s query as-is. Transform it:
Query expansion: Generate multiple variations of the query
Hypothetical document embeddings (HyDE): Generate what an ideal answer would look like, then search for that
Step-back prompting: Ask broader questions first to establish context
Example: User asks “What’s the ROI calculation?”
Transform to:
“Return on investment formula”
“How to calculate ROI”
“ROI = (Net Profit / Cost of Investment) × 100”
Search with all three, get better coverage.
Metadata Filtering
Rich metadata is your friend. Tag your chunks with:
Document type
Date/version
Author
Department
Confidence scores
Then filter before or during retrieval. If someone asks “What’s our current policy on X?” you can filter to only policy documents from the last 6 months.
Retrieval Evaluation
You can’t improve what you don’t measure. Track:
Retrieval precision: What % of retrieved chunks are actually relevant?
Recall: Are you finding all the relevant information?
MRR (Mean Reciprocal Rank): How quickly do you surface the best results?
User satisfaction: Are people getting what they need?
Build eval datasets. Test continuously. Iterate.
The Agent Layer
Here’s where it gets interesting. The most sophisticated RAG systems don’t just retrieve once—they reason about retrieval.
Agentic RAG workflow:
Analyze the query
Determine if you need to search (maybe the LLM already knows this)
Formulate search strategies
Execute multiple searches if needed
Evaluate retrieved context quality
Search again if necessary
Synthesize the final answer
This is expensive (more tokens, more latency) but dramatically more capable. It’s the difference between a search engine and a research assistant.
Practical Implementation Patterns
Pattern 1: The Router
Not all queries need RAG. Use a lightweight classifier to route:
Direct to LLM: General knowledge questions
Simple RAG: Straightforward factual lookups
Agentic RAG: Complex analytical queries requiring synthesis
Pattern 2: The Citation System
Make your system cite sources. Not just for trust, but because:
It forces better retrieval (you can’t cite irrelevant chunks)
Users can verify and dig deeper
You can track which sources are most valuable
Pattern 3: The Feedback Loop
Capture implicit and explicit feedback:
What did users search for?
Did they rephrase their query?
Did they click thumbs up/down?
Did they engage with the result?
Feed this back into your system to improve over time.
What Actually Breaks in Production
Let me save you some pain. These are the real issues:
Embedding model drift: User queries and document styles change over time. Your embeddings become less effective. Solution: Monitor retrieval quality, consider periodic reindexing.
Cold start problem: New documents added to your system don’t have usage data or feedback yet. They get retrieved less often, even when relevant. Solution: Boost new documents temporarily.
Query ambiguity: “What’s our position on remote work?” Could mean policy, office space strategy, or company values. Solution: Clarification prompts or multi-interpretation retrieval.
Context window constraints: You can’t just dump 50 chunks into Claude and hope for the best. Solution: Intelligent pruning, summarization, or progressive retrieval.
The Economics of Context
Every retrieved chunk costs tokens. Every reranking step costs time. You need to optimize:
Latency: Users won’t wait 30 seconds for an answer
Cost: Token costs add up at scale
Quality: But not at the expense of correctness
The sweet spot varies by use case. A customer support chatbot needs speed. A legal research tool needs comprehensive recall. Know your priorities.
Looking Forward
The future of context engineering isn’t about more complex retrieval strategies (though those help). It’s about systems that:
Learn from usage: Continuously improve based on what works
Explain themselves: Show their reasoning and sources
Know their limits: Admit when they don’t have good information
Collaborate with humans: Make it easy to provide feedback and corrections
Context Engineering 2.0 is about building systems that work reliably, scale gracefully, and improve continuously.
Key Takeaways
Retrieval quality is your bottleneck—invest there first
Hybrid search + reranking beats pure vector search
Query transformation dramatically improves coverage
Measure everything; you can’t improve what you don’t track
Agentic patterns unlock new capabilities but cost more
Design for production from day one, not as an afterthought
The gap between a RAG demo and a production system is significant, but not insurmountable. Focus on the fundamentals, measure relentlessly, and iterate based on real usage.
That’s Context Engineering 2.0. Now go build something that actually works.
What challenges are you facing with your RAG systems? Drop a comment—I’d love to hear what’s working (and what’s not) for you.
Thanks for the simple walkthrough for the good 😊